
这个专栏将介绍如何使用高通的QNN SDK部署一个自己训练的端到端头部位姿估计模型。我使用的平台是高通的汽车级8775处理器,是面向下一代的舱驾融合平台。开发环境是Ubuntu 22.04。由于高通的部署工具链是闭源且门槛费高昂,参考的资料很少,所以本文将以自己的经验和理解为主,介绍如何使用QNN SDK部署一个端到端头部位姿估计模型,模型用于DMS/OMS等专用应用。
1- 环境安装
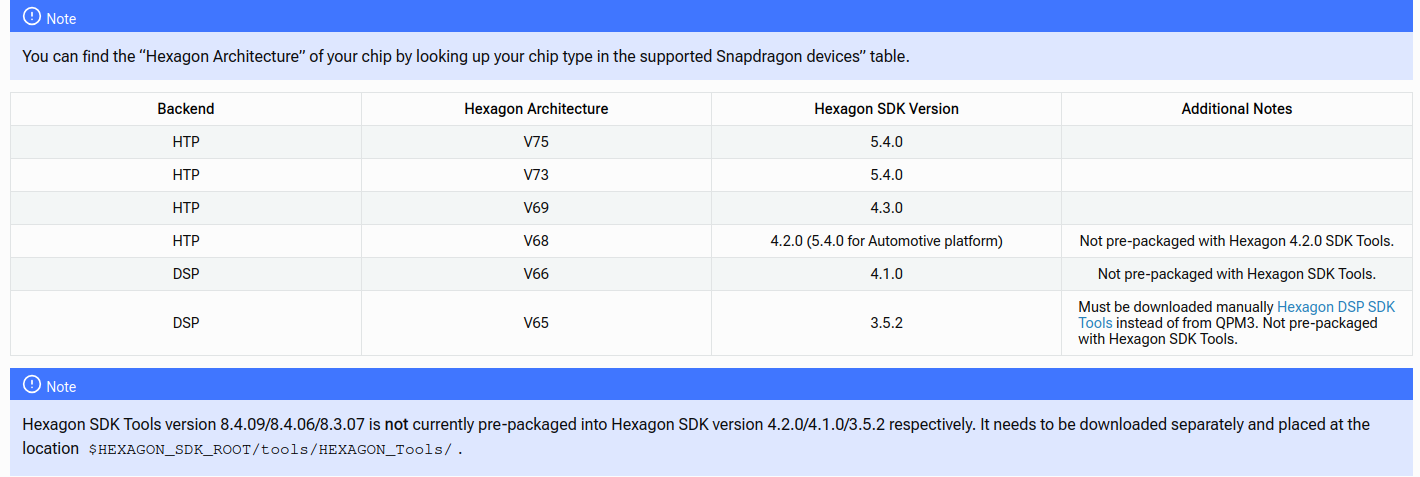
从2.3.4QNN SDK的手册来看:
使用HTP,是V73版本的架构,Hexagon SDK 版本为5.4.0
qnn_python环境
1 | # 1-创建虚拟python环境, qnn2.3.4版本只支持这个python版本,请注意 |
这里要注意了,因为是在国内,所以说高通提供的安装脚本非常慢并且基本是失败的。这时候需要修改高通QNN_SDK中环境配置的python脚本${QNN_SDK_ROOT}/bin/check-python-dependency,为其添加清华源,保证快速安装。
1 | #!/usr/bin/env python3 |
对脚本修改完成后,执行,将会自动安装,如果遇到没办法安装的库,使用pip install xxxx 进行手动安装,我在安装的时候,matplotlib这个就遇到了不成功的问题,直接用的手动安装。脚本执行完成后,还需要安装一些额外的库,根据自己使用的框架和方法来选择就行,我使用的是pytorch和onnx,所以根据文档: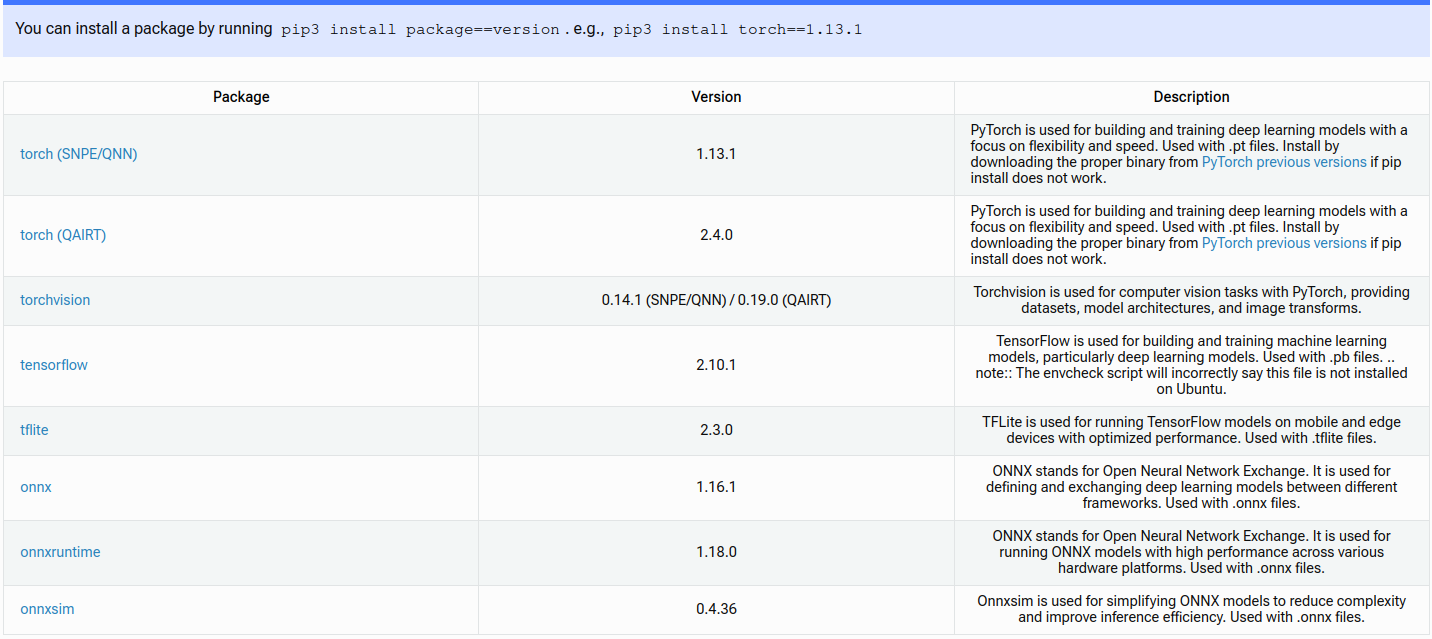
这里需要额外安装:
1 | pip install onnx==1.16.1 -i https://pypi.tuna.tsinghua.edu.cn/simple |
我训练模型和pth转onnx是在另一个环境上进行的,所以这里是没有安装torch的,我已经有了处理好的onnx模型。记得在导出模型的时候,将模型进行简化。
qnn_Android_NDK
由于我部署的目标系统是8775的安卓平台,所以需要NDK的支持。所以需要在Host开发机器上配置好NDK的环境。
1 | # 下载对应的版本,参见QNN的文档:file:///home/cty/hsae_data/qnn/qnn_sdk_v2.34.0_auto_qnx/qaisw-v2.34.0.250424201103_119471-auto-qnx/docs/QNN/general/setup/linux_setup.html |
激活环境和预备
1 | # 环境激活 |
2-模型的转换、量化
非量化模型的步骤
首先将pth模型转化为ONNX模型,记得打开模型简化
1 | qnn-onnx-converter -i '/home/cty/self_project/DMS/6DRepNet/model_file/test_qnn.onnx' -o '/home/cty/self_project/DMS/6DRepNet/model_file/no_quanti_qnn.cpp' |
使用这个指令将模型转化为非量化版本的QNN模型,将会得到no_quanti_qnn.bin以及no_quanti_qnn.cpp还有一个json文件
量化模型的步骤
1 | # 上面的是不量化的指令,如果要简单量化,需要使用额外的参数--input_list |
这里着重备忘一下如何制作量化所需要的数据,首先,这些数据是图像数据没错,要核对数据的尺寸,比如说这个网络的输入是3 x 244 x 244的图像,那么我就随机抽取测试集中的500张图像,并下采样到指定的224x224,然后拷贝到一个指定的位置,并将这些图像(一般是JPEG之类的压缩了的),归一化转化为bin文件,然后制作出相应的txt文件。
1 | import os |
执行之后,会得到量化后的模型,当然,也可以指定一些额外的参数来控制量化模型的精度,效果,大小,通道等等。
1 | 2025-07-24 15:23:37,314 - 270 - INFO - Saving QNN Model... |
量化细节
1. 指定量化输入数据
1 | --input_list INPUT_LIST |
- 用途: 指定用于量化校准的输入数据文件路径。
- 说明: 这是一个文本文件,每一行包含一个或多个二进制文件路径,每个文件包含一个输入数据(如图像、张量等)。
- 示例:其中
1
--input_list calibration_data.txt
calibration_data.txt内容如下:1
2/path/to/input1.bin
/path/to/input2.bin
2. 设置权重和激活的量化位宽
1 | --weights_bitwidth WEIGHTS_BITWIDTH |
- 用途: 分别设置权重、激活值和偏置的量化位宽。
- 默认值:
--weights_bitwidth: 8--act_bitwidth: 8--bias_bitwidth: 32
- 可选值:
weights_bitwidth:4或8act_bitwidth:8或16bias_bitwidth:8或32
- 示例:
1
--weights_bitwidth 8 --act_bitwidth 8 --bias_bitwidth 32
3. 激活值和权重的量化校准方法
1 | --act_quantizer_calibration ACT_QUANTIZER_CALIBRATION |
- 用途: 设置激活值和参数(权重)的量化校准方法。
- 可选值:
min-max(默认)sqnrentropymsepercentile
- 示例:
1
--act_quantizer_calibration min-max --param_quantizer_calibration min-max
4. 激活值和权重的量化模式
1 | --act_quantizer_schema ACT_QUANTIZER_SCHEMA |
- 用途: 设置激活值和参数(权重)的量化模式(对称/非对称)。
- 可选值:
asymmetric(默认)symmetricunsignedsymmetric
- 示例:
1
--act_quantizer_schema asymmetric --param_quantizer_schema symmetric
5. 启用逐通道量化
1 | --use_per_channel_quantization |
- 用途: 启用卷积层权重的逐通道量化,提高精度。
- 示例:
1
--use_per_channel_quantization
6. 启用逐行量化
1 | --use_per_row_quantization |
- 用途: 启用全连接层(Matmul)的逐行量化。
- 示例:
1
--use_per_row_quantization
7. 忽略模型自带的量化信息
1 | --ignore_encodings |
- 用途: 忽略模型中自带的量化编码信息,仅使用量化器生成的编码。
- 注意: 不能与
--quantization_overrides同时使用。 - 示例:
1
--ignore_encodings
8. 使用量化覆盖文件
1 | --quantization_overrides QUANTIZATION_OVERRIDES |
- 用途: 指定一个 JSON 文件,其中包含自定义的量化参数,覆盖默认的量化行为。
- 示例:
1
--quantization_overrides quantization_overrides.json
9. 启用浮点回退
1 | --float_fallback |
- 用途: 当某些节点无法量化时,回退到浮点计算。
- 示例:
1
--float_fallback
10. 百分位校准值
1 | --percentile_calibration_value PERCENTILE_CALIBRATION_VALUE |
- 用途: 用于
percentile校准方法的百分位值(90 到 100 之间)。 - 默认值:
99.99 - 示例:
1
--percentile_calibration_value 99.9
量化示例
假设你有一个 ONNX 模型 model.onnx,并且你已经准备好了校准数据 calibration_data.txt,你可以使用以下命令进行量化:
1 | qnn-onnx-converter \ |
这个命令会使用 8 位量化权重和激活值,并启用逐通道和逐行量化,确保模型在保持精度的同时具备高效的推理能力。
4-部署至目标设备
为指定的目标设备编译模型so库
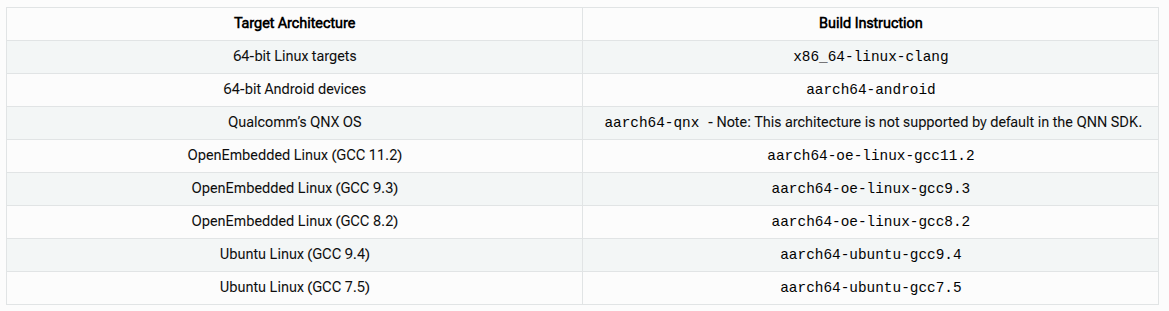
这里我使用的是高通的SA8775P汽车芯片平台,系统架构采用的QNX上虚拟出Android,所以是aarch64-android目标平台或者x86_64-linux-clang平台
1 | export QNN_TARGET_ARCH="your-target-architecture-from-above" |
我自己的主机是一个x86_64的Linux主机,在qnn的bin下面有qnn-model-lib-generator,执行,其中-c和-b是之前量化模型得到的目标文件,-o是输出的位置folder
[!NOTE] qnn-model-lib-generator
c - This indicates the path to the .cpp QNN model file.
b - This indicates the path to the .bin QNN model file. (b is optional, but at runtime, the .cpp file could fail if it needs the .bin file, so it is recommended).
o - The path to the output folder.
t - Indicate which architecture to build for.
1 | NOTE:在转x86_64-linux-clang库的时候,会出现一些问题 |
1 | python3 "${QNN_SDK_ROOT}/bin/x86_64-linux-clang/qnn-model-lib-generator" \ |
随后我们就得到了相应的so:libtest_qnn.so,这里编译HTP的so库是以HTP为后端的。
部署在指定的计算后端上
构建的模型和所有必要的文件传输到目标处理器,然后对其运行推理,这里我希望推理后端是DSP/HTP,也就是高通的计算芯片,他们命名很复杂,抛开这些,知道后端是DSP在做计算芯片即可。根据项目的需求,既可以是CPU,也可以是GPU,也可以是DSP
DSP 处理器需要量化模型而不是全精度模型。如果您没有量化模型,请按照 CNN 到 QNN 教程的第 2 步构建一个。
接着,要去找一下芯片对应支持的Hexagon架构和工具链
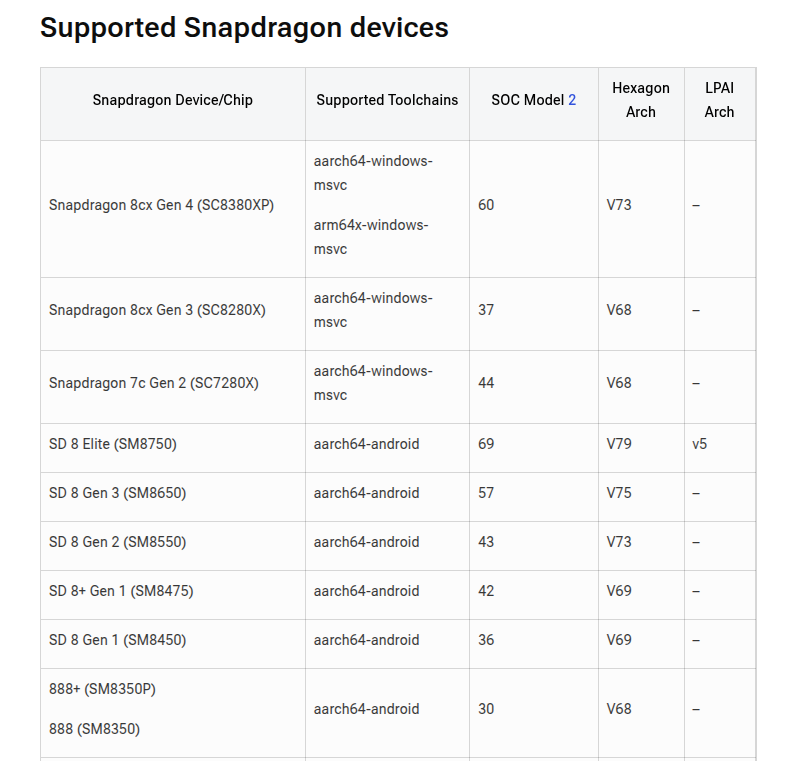
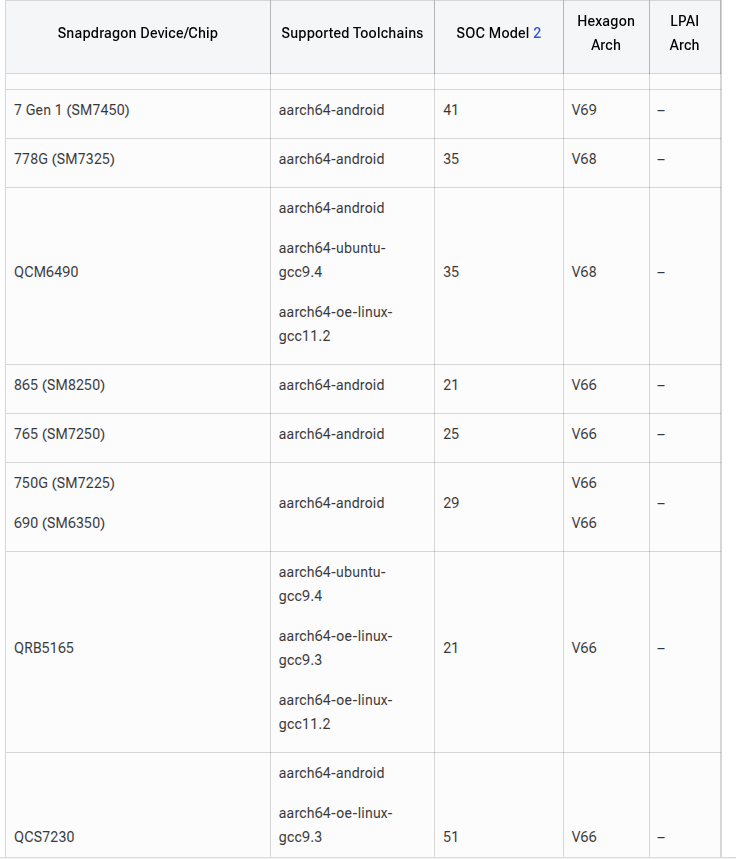
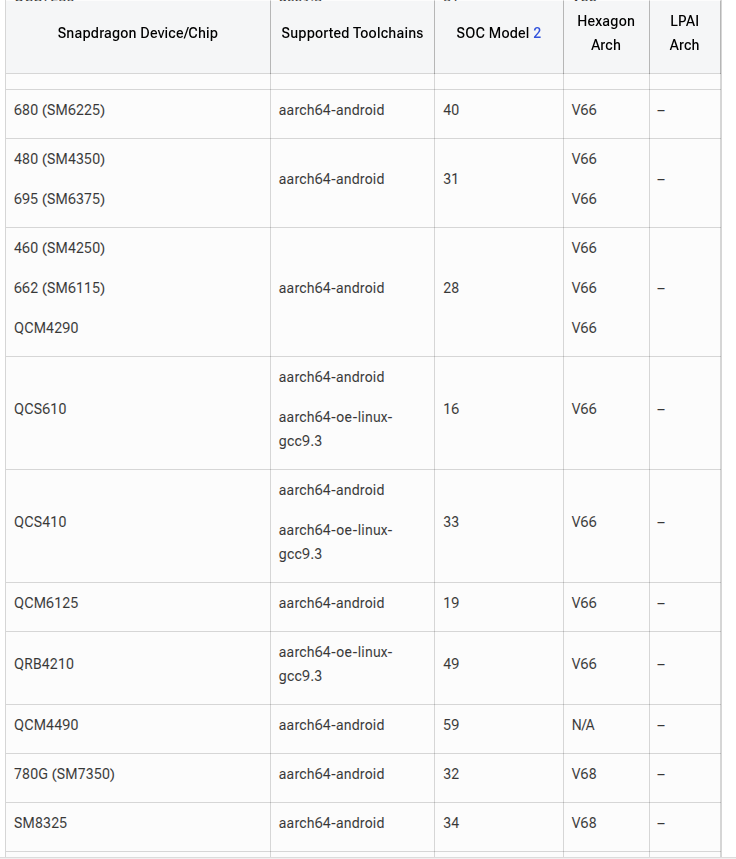
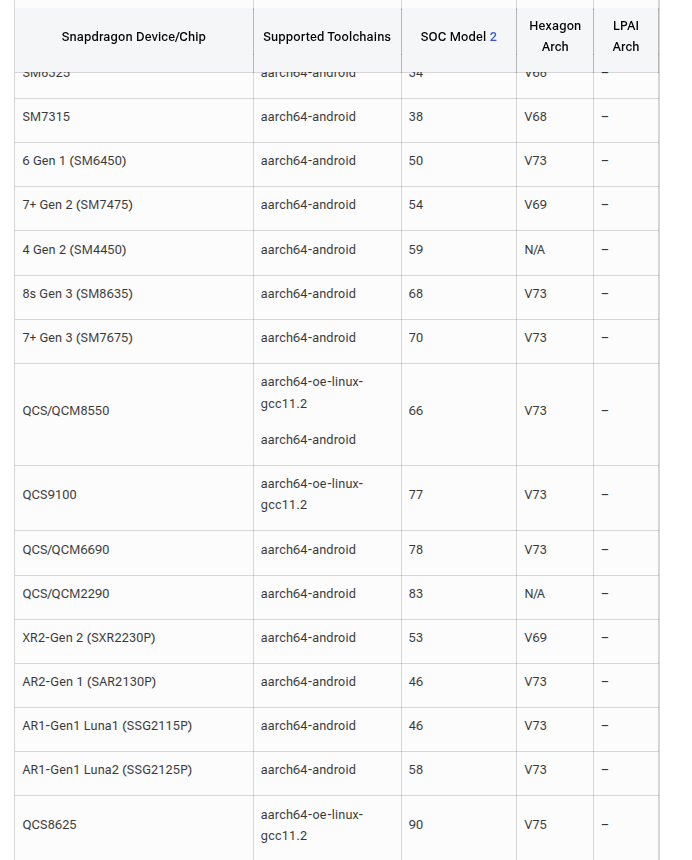
这里看起来大部分是手机的,对于汽车的平台,应该参照对应的SDK的手册。这个在一开始的环境配置里有写
部署在GPU上进行推理(QNX)
1-使用非量化版本的so
注意,这个地方需要QNX710系统的环境,一个是授权文件.qnx,一个是QNX环境
1 | source /home/cty/hsae_data/qnx/qnx_710_envs/qnx_710/qnxsdp-env.sh |
在之前我们使用量化版本的模型得到了so,现在要使用非量化的模型来,我命名为no_quanti_qnn
1 | export QNN_TARGET_ARCH="aarch64-qnx" |
于是得到了相关的libno_quanti_qnn.so
2-推送到目标设备上
1 | adb devices |
3- 查看运行结果并可视化
运行完成后,会产生一个output文件夹,由于我只测试了一张图像,txt里只有一张图像,要看结果只能把文件从QNX里导出来到安卓再导出来到上位机
1 | # 在安卓端运行: |
我这里使用的模型是一个很小的回归模型,通过写一个py脚本来解析raw的数据,并对其可视化,并使用上位机的推理结果来验证,可以看到以下的结果: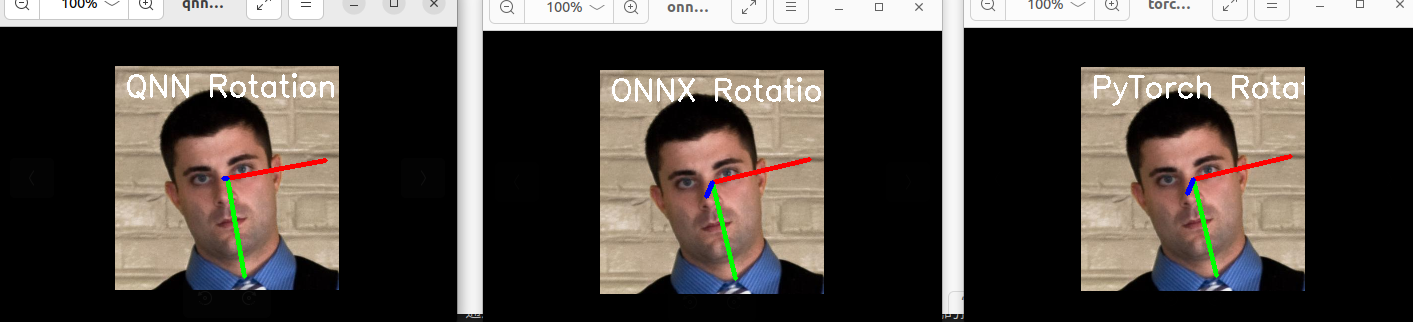
可以看到,QNN的执行结果和原始模型的推理结果还是存在一定的差距,但基本正确,这和很多因素有关系。
部署在HTP上进行推理(QNX)
1-序列化模型(HTP)
1 | "$QNN_SDK_ROOT/bin/${QNN_TARGET_ARCH}/qnn-context-binary-generator" \ |
将会得到类似以下的输出
1 | # 输出如下: |
2-推送相关的文件到目标设备上(QNX)
8775P的HTP(DSP)对应的Hexagon架构是V73,
1 | +---------+----------------------------+--------------------+----------------+ |
接着在目标设备上创建相应的一个目录用来放模型和库
1 | adb devices |
3-查看运行结果并可视化
1 | ## 运行完成后,会产生一个output文件夹,由于我只测试了一张图像,txt里只有一张图像,要看结果只能把文件从QNX里导出来到安卓再导出来到上位机 |
可视化方法和之前的一样,只不过是解析量化后的数据
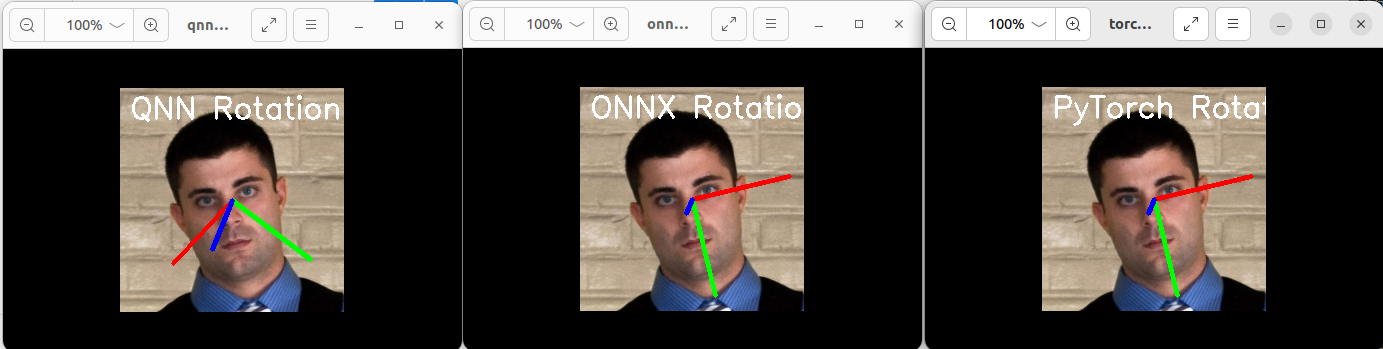
QNN量化后的结果完全是错误的,量化损失的精度太多,基本让模型失效了,这个问题可以从后续分析,针对某些导致精度下降的层进行修改和修复。