
操作系统OS
这份笔记是在学习操作系统课程时候所记录的备案,希望能在以后的工作,生活中常常看看,温习复习,温故而知新。我学习的路线是南大蒋教授开设的春季班,欢迎大家到蒋教授的个人主页去观看和学习:蒋教授的主页
课程的讲义都放在了这个tag下面,整个章节全部一起,没有分P,直接食用。
自己因为课题繁忙和实习的原因,断断续续在学习,实在惭愧。
在开始之前,要求我们有基本的C语言基础:[C语言参考手册](C 参考手册 (shucantech.com))
1、操作系统概论,为什么要学习操作系统
害,说起来操作系统这个概念在我很小的时候就接触了,但是那时候整天混在语数外理化生的填鸭里,即使有兴趣也没办法实践和操作。
为什么鼠标会动,为什么屏幕会亮,为什么点击鼠标就能选中文件,为什么会有一个空洞的的命令行。
好,这些问题最后都可以在学习操作系统中得到解决。因为带着问题,需要求解,现代社会所使用的电子设备,手机、电脑、汽车主控,全部都会使用到操作系统,当然单片机这些没有操作系统的,裸机不使用操作系统也能运行(现在RTOS这些实时操作系统也应用得很广泛了),基于这一切的问题,我希望把过往的开发经验和过去尚未掌握的知识总结和提炼,让自己的内功提升一个等级。
1 | PS:好吧,说来惭愧,身为一个未来的工程师,其实408的这些课程真的是我到了研究生阶段才好好形成系统的。 |
当然,狭义的操作系统,就是管理计算机硬件,抽象硬件,为程序提供服务。对操作系统来讲,给它下一个定义太难,滴水不漏的定义实在是太味同嚼蜡。
广义地来说,甚至浏览器也可以看作一个操作系统,hadoop也算,哈哈哈哈,当然这是狭义的。服务于应用程序的应用程序,它是“支持”的程序。
所有复杂的东西都是由简单的东西变来的,好,我们从一台裸机入手来看,我们有一组机器码,二进制,它代表00010001,要做一个加法加上10001000,好家伙,怎么加?哎嘿,突然就记忆起了模电数电对吧,用高电位表述1,低电位表述0。那么就搞个电路来记忆,锁存器,逻辑门,延迟线!假设现在有两个这样的可以记忆8位的单元,去做一个这样的操作,用纯电路来实现。在1940年起始的时候计算机的雏形,用的就是逻辑门,延迟线,纸带,实现了计算,存储和输入输出。
这时候算是操作系统吗?当然不算,因为软件和硬件的抽象都没有完全分开。
到了1950年,出现了更小的逻辑门,更大的内存(磁芯内存),更多的IO设备,这个时候,io的速度和处理的速度就匹配不上了,于是在1953年,出现了中断机制。当然,这个重要的机制,是现代计算机的基石之一,后面讲它为什么出现。这个时候的计算机,会执行更多更复杂的任务,使用计算机的人越来越多,希望直接调用api而不是直接接触硬件。Fortran 作为第一个语言出现了,好吧,它仍然是用纸带,而在今天,我们有那么便利的集成开发环境,不用再去数纸带了。
那时候,每一个软件,或者说卡片(纸带),一个学校,只有一台计算机,但是数学系要用,化学系要用,物理系也要用,咋办?排队纸带?于是需求出现了:多用户排队共享计算机。当然不是每个系的学生排队。于是出现了操作系统的概念。操作–任务–系统。想象一下,管理员晚上把所有的卡带放在一个可以自动切换的小机器上,然后把每一张卡片计算后的结果写到某个空的纸带上,早上一起来,大家的东西都算完了,然后,是不是文件的概念就出现了呢。
这就是批处理系统的雏形,就像程序的自动切换(换卡)+库函数api,这个时候DOS出现了,操作系统中出现了设备,文件,任务等对象和api。
这个年代的计算机,一个时间段,只能执行指定的那个文件,内存很小不支持很大的计算。后来,出现了更大的内存,这个时候就可以把两个甚至多个程序放在内存里了,哈哈哈哈。但是这个时候只有一个计算用的核心,咋办?又出现了问题,我们这时候的打印机,处理数据需要5s,但是打印要5分钟,这5min难道都要cpu等它打印完吗??于是出现了中断,一个执行一会儿,谁优先级高先弄谁,这是很自然的想法,把cpu的资源共享了起来。
1 | 同时将多个程序载入内存是一项巨大的能力,这是跨时代的! |
操作系统自然而然地增加了进程管理的API。这个时候:multi_program出现,多任务的时候,互相分隔的两个程序,坏了一个并不会影响另外一个。总的来说,这个时候出现的操作系统,已经和现代操作系统雏形很接近了,比如说A程序运行10ms,然后是OS调度,然后程序B运行10ms,然后OS调度,依次类推。OS就把任务给管理起来了。既然操作系统可以在程序之间切换,为什么不让他们定时切换呢?于是,基于中断机制:
1 | 时钟中断,使得程序在执行的时候,异步地插入函数调用 |
1960年代的到来,出现了更多的高级语言和编译器,比如说BASIC。
1970年代的到来,集成电路空前发展,个人电脑兴起,计算机已经与今天无大异。PASCAL语言…..可以在字符终端上编程
CISC指令集出现,中断、IO、异常、MMU、网络。分时系统走向成熟,UNIX走向完善,奠定了现代操作系统的形态。
1 | 1973信号API、管道(对象)、grep(应用程序) |
今天的操作系统:通过虚拟化硬件资源,为程序提供服务的软件。又提到了虚拟化这个名词。
1 | 空前复杂的系统出现 |
总结:
理解操作系统的三个根本问题:
1、操作系统服务谁? 程序 = 状态机
课程涉及:多线程Linux应用程序
2、操作系统为程序提供什么服务?
操作系统 = 对象 + API
课程涉及: POSIX +部分Linux特性
3、如何实现操作系统提供的服务?
操作系统 = C程序
完成初始化后就成为:interrupt/trap/fault handler
课程设计:xv6 自制迷你操作系统
2、什么是操作系统中的程序?状态机
有意思的是,在以往的学习中,我们并无从得知为什么程序可以运行,好在我最早熟悉的语言是汇编,在一堆MOV和JUMP中迷失自我23333,用更形象的话来说,操作的数据本身DATA-SEGMENT是内存和寄存器,那么其实就是内存和寄存器中的数据体的状态随着一个个指令在不断地转化,其实绝大部分指令都是计算,例如ADD,每次M(内存)、R(寄存器)中的值随着时间一个个状态进行转移,这就是最朴素的理解。
指令有两种:
1 | 1、计算:所有我们见到的程序,本质上都是计算 |
但是在更多的时候,例如我们要显示一张图片,只能说我们的进程把一个2D的矩阵计算出来放在内存里,但是要在输出设备上显示出来就不是这个进程做的事情了,而实际上,要显示,就是这个进程去呼叫操作系统,然后操作系统帮我们帮这张图片输出出来。操作系统会帮我们解决,操作系统会干剩下的事情,应用不需要它是怎么干的,这就是应用眼中的操作系统。
1 | 有办法让状态机停下来嘛?? |
其实“状态机视角”下的程序只需要这样朴素的理解(当然它非常复杂,但是为了理解必须做出抽象和简化),在C/CPP视角下的状态机,就是变量和栈帧随着时间一次次进行状态改变,在Asm视角下,就是内存M和寄存器R随着时间一次次进行状态改变。这两者其实是有直接的联系的,联系这两者的就是complier,编译器。那么状态机顺便解决了一个重要的问题,什么是编译器???
我们在工作中经常使用gcc、g++,还有各种交叉编译的编译器。这玩意儿是啥?感性理解其实很简单,让机器读懂代码的软件就是编译器,更不要说大一就学了预处理编译链接这样的知识。
1 | 编译器:源代码C(状态机)-->二进制代码S(状态机) |
一个更基本的问题是:什么是正确的编译(优化)? S和C的可观测行为严格一致
正确的,但是低效的:就是直接执行,直接翻译
现代的编译优化: 保证观测一致性的前提下改写代码
但也有需要超稳定的编译器的场合,比如说,某些没办法修bug的场合,例如上天的飞行器,编译它内部代码的编译器要求100%的正确性(当然这个是数学上被证明可以实现的)
1 | 举个例子,例如一个全局变量,它不能被优化掉,因为有可能别的代码也会使用它 |
操作系统中的一般程序:程序 = 计算 -> syscall -> ...
操作系统收编了所有的硬件和软件资源,只能用操作系统允许的方式访问操作系统中的对象,从而实现操作系统的霸主地位。这是为管理多个状态机所必须的,不能打架,谁有权限就给它。
1 | 状态机(程序) |
二进制文件(程序)也是操作系统中的对象,可执行文件与我们日常使用的a.c README.md没有本质上的区别,操作系统提供API打开、读取、改写(都需要相应的权限)
查看可执行文件:
vim cat xxd 都可以直接查看可执行文件
系统中常见的应用程序:例如GNU CoreUtils,系统工具程序(bash、apt、vim、ssh、jdk、python、binutils…..)这些工具都是由开发者来实现的,例如apt就是dpkg的壳。还有什么浏览器,音乐播放器…..所有的这些程序,最后都是计算加syscall的总和。
1 | 善用工具来弄明白状态机(程序)在做什么? |
状态机的执行
1 | 进程管理:fork execve exit ... |
直到_exit(exit_group)退出
所有的软件,都是这么去理解,浏览器,杀毒软件,编译器都是这样的。
YES!!!这些API就是操作系统的全部!
1 | 编译器gcc,代表其他工具程序 |
各式各样的应用程序都在操作系统 API (syscall) 和操作系统中的对象上构建
1 | 窗口管理器 |
总结
1 | Q: 到底什么是 “程序”? |
程序在执行的时候,分为堆\栈。而程序执行时候,栈帧在不停地改变。内部的变量产生又销毁。
3、线程,并发,现代处理器与宽松内存模型
这节课的主要内容
1 | 1、并发程序的状态机模型 |
线程是CPU调度的最小单位。这个概念很微妙。我们在以前学过原子操作。
所有的应用程序本身都只能改变内存的状态,而剩下的东西是由操作系统来完成的。
在多处理器时代,程序视角下和上一章讲的单线程有什么不同呢?这一节来讲这个问题。
并发
操作系统是最早的并发程序之一:系统调用的代码,就是最早的并发程序。
今天遍地都是多处理器系统,为什么?
并发的基本单位 线程 :共享内存的多个执行流
执行流拥有独立的堆栈/寄存器
共享全部的内存 (指针可以互相引用)
1 | {全局变量 malloc} ----> (全局共享的元素Global) |
并发就体现在,我们在每一个状态,是选择T1 or T2
当我选择T1执行的时候,相当于在当前时间片,是T1和共享元素共同构成一个单线程的状态机,然后执行一步,执行完后,产生新的Global、T1,T2不变,然后又从这个新的状态,选择T1 or T2。当然,选择T2执行的时候,同理。这个过程会不断进行,直到所有状态机结束。c
那么问题来了,并发程序的每一步,如果没有条件限定、没有边界或者控制,那将会产生无序。下面这段代码展示了一个非常简单的多线程实现方法
一个最简单的多线程库
1 |
|
Linux 中的 pthread_create() 函数用来创建线程,它声明在<pthread.h>头文件中,语法格式如下:
1 | int pthread_create(pthread_t *thread, |
1 |
|
如何证明线程确实共享了内存?又如何验证每个线程使用的栈的地址空间大小?
1 |
|
另外,也可也使用strace去查看和跟踪系统调用,于是我们看到了clone系统调用:它就是与创建线程相关的。最重要的是,我们要学会看手册:man 7 pthreadsPOSIX为我们提供了线程库pthreads,我们可以参考手册去改写上面写的代码,使得线程拥有更大的栈。
巨大的问题来了当我有两个线程,同时执行x++,结果是?
这个问题很大哈,比如说我们有两个线程同时去访问一个复杂的数据结构,那这个结构会怎么样呢,往同一个链表里同时写一个东西,会怎么样呢???
最难的部分来了。接下来引入:
原子性(互斥)
1 | //喵喵支付宝 |
两个线程并发支付100块会发生什么?????
1 |
|
我们可以从上面这个例子看到,同时支付的时候:
balance = 18446744073709551516
账户里会多出用不完的钱!
Bug/漏洞不跟你开玩笑:Mt. Gox Hack 损失650,000比特币:今天价值 $28,000,000,000
再看一个小实验
1 | //分两个线程,计算 1+1+1+...+11+1+1+…+1 (共计 2n个 1) |
1 | /* |
编译器对内存访问的eventually consistent暨最终结果一致性也会导致共享内存作为线程同步工具的失效
在上面我们观察的现象,编译器带来的优化,是直接改变了汇编层面上的执行状态机结构的。当然,多个线程访问同一个数据结构在没有手段的情况下肯定是unsafe的,这不是优化带来的问题。
来看这个例子:
1 |
|
编译:gcc -o out_set/mem-ordering.out mem-ordering.c -lpthread
如果说结果不好观察可以这样:./mem-ordering.out | head -n 500000 | sort | uniq -c
原子性:一段代码执行 (例如 pay()) 独占整个计算机系统
- 单处理器多线程
- 线程在运行时可能被中断,切换到另一个线程执行
- 多处理器多线程
- 线程根本就是并行执行的
实现原子性。任何自作聪明的想法,都会搬起石头砸自己的脚。在并发这个问题上,99%的问题都可以用一个队列来解决。互斥和原子性是本学期的重要主题
lock(&lk)unlock(&lk)- 实现临界区 (critical section) 之间的绝对串行化
- 程序的其他部分依然可以并行执行
99% 的并发问题都可以用一个队列解决
- 把大任务切分成可以并行的小任务
- worker thread 去锁保护的队列里取任务
- 除去不可并行的部分,剩下的部分可以获得线性的加速
- 其实我们日常使用的高级语言例如Java和Python都有考虑到这些,有现成的轮子
现代处理器:处理器也是 (动态) 编译器!
单个处理器把汇编代码 (用电路) “编译” 成更小的 μops,嘿嘿嘿,汇编代码也是可以拆分的,没想到吧?
1 | - RF[9] = load(RF[7] + 400) |

在任何时刻,处理器都维护一个μop 的 “池子”
- 每一周期向池子补充尽可能多的μop
- “多发射”
- 每一周期 (在不违反编译正确性的前提下) 执行尽可能多的μop
- “乱序执行”、“按序提交”
- 这就是《计算机体系结构》 (剩下就是木桶效应,哪里短板补哪里)
- 可以看这个链接,这个作者也是学习的本课程博客
我们的现代处理器,就是一个动态的数据流处理中心。多处理器编程下,程序的理解要有相应的变化。
1 | 多处理器程序 = 状态机 [ 共享内存;非确定选择线程执行] |
4、理解并发程序的执行
并发程序 = 多个执行流、共享内存的状态机
如何理解教科书、互联网上的各种并发程序??
主要内容:画状态机理解并发程序
临界区
在开始后面的内容之前一定要厘清临界区的定义:
临界区指的是一个访问共用资源(例如:共用设备或是共用存储器)的程序片段,而这些共用资源又无法同时被多个线程访问的特性。当有线程进入临界区段时,其他线程或是进程必须等待(例如:bounded waiting 等待法),有一些同步的机制必须在临界区段的进入点与离开点实现,以确保这些共用资源是被互斥获得使用,例如:semaphore。只能被单一线程访问的设备,例如:打印机。
或者说,一个资源任意时刻(时间片)只能允许被一个线程访问,这个资源叫临界资源。正在访问临界资源的那段程序叫临界区。
互斥算法
互斥:保证两个线程不能同时执行一段代码
回到上一章的代码:
1 | //分两个线程,计算 1+1+1+...+11+1+1+…+1 (共计 2n个 1) |
插入某个代码,能否使得sum.c正常工作呢?假设一个内存的读写可以保证顺序,原子完成。其实理解这个也不难,两个线程同时访问某个数据,数据被修改与否,另外一个线程是不知道的,并且,线程如果没有先后顺序的话,则数据本身就会出问题(例如说本来只应该被修改一次的数据被修改两次)。进入临界区,例如说两个线程同时竞争一个资源,肯定会打架对吧,那么手快有手慢没有这样是成立的吗?能实现互斥吗?任何时候只有一个线程在临界区是可以实现的吗?为了证明某个算法的互斥性,画状态机来看。
想要用共享内存来实现并发程序,是个需要非常小心的过程
画状态机实在是太累了,这样的一个算法状态机,万一画错了,或者没想到一些corner-case,很小的地方就会导致全部错误。有没有办法写一个程序枚举所有的状态呢?来看这两个程序。
1 | import inspect, ast, astor, copy, sys |
1 | class Mutex: |
如果要可视化的话,也可也用管道把输出给一个可视化脚本:visualize.py
生成的html文件可以直接用浏览器打开看,将观察到状态机的每一个状态。在绝大部分情况下,写的程序都是正确的,但是这个状态机真的全部正确吗?不一定,我们的状态空间里面有很多状态,而这个视角下相当于把计算机线程的问题转化为了一种图论问题。
可视化之后我们看到了这个有向图,给一个起点初试状态,若有一条路径到一个错误的状态,那么说明程序本身是unsafe的;若没有这样一条的路径,那可以证明,程序是线程安全的。即是否从任何状态出发,都能在有限的步骤里,(无论线程怎么调度),都能到达一个安全的节点(临界区只有一个线程)。在上面的例子里,这个状态机特别特别复杂,能简化它吗?能否用一个树来表达呢?能否控制和简化这张图呢?这个我们在后面继续探索。
我们需要Model checker工具来帮助我们理解这个复杂的状态机,并且使用这些工具来帮助我们少写bug。操作系统是一个巨大的工程,没有编程,测试,调试的工具怎么才能写呢。没人能阻止程序员写bug,但是工具可以。
并发
并发程序 = 状态机 —线程共享内存 — 每一步非确定选择线程执行
画状态机就对了:当然要用工具:Model checker
5、并发控制:互斥: 、自旋锁、互斥锁、Futex
这一节的主题:怎么样正确的在多处理器上实现高效率的互斥呢?
共享内存上的互斥
回顾一下上一届的并发编程,线程 = 大脑能完成局部存储与计算 ; 共享内存 = 物理世界(物理世界天生并行) 一切都是状态机。
先抛出一个点: 持有一把具有排他性的锁,当前资源是被保护的,别人是无法使用被锁保护的资源。如果某个线程持有锁,则其他线程不能返回或者访问这个线程正在访问的资源。为啥在共享内存上实现互斥这么困难呢?本质是原因是:不能同时读 / 写共享内存,写的时候不知道里面的状态,读的时候不知道这个状态是不是对的,也不知道把什么改成了什么。目标:要用简单粗暴有效的方式解决互斥这个问题。
5-1 自旋锁(Spin_lock)
解决问题的两种方法
提出算法、解决问题 (Dekker/Peterson/…’s Protocols)
或者……> 改变假设 (软件不够,硬件来凑)
假设硬件能为我们提供一条 “瞬间完成” 的读 + 写指令
- 请所有人闭上眼睛,看一眼 (load),然后贴上标签 (store)
- 如果多人同时请求,硬件选出一个 “胜者”
- “败者” 要等 “胜者” 完成后才能继续执行
Atomic exchange (load + store)
1 | int xchg(volatile int *addr, int newval) { |
更多的原子指令:stdatomic.h (C11)
我们来看这个例子X-86原子操作:LOCK指令前缀
1 | //分两个线程,计算 1+1+1+...+1+1+1+…+1 (共计 2n个 1) |
这和之前的代码是一样的,两个线程同时计算和写入sum。有区别的地方是这一句内联汇编:asm volatile("lock addq &1, %0": "+m"(sum));这里,就是使用了系统提供的保护,暨在当前线程执行的时候保护sum的值不被另外的线程访问。这个程序就能得到正确的结果。
实现互斥:自旋锁
1 | int table = YES; |
1 | int locked = 0; |
原子指令的诞生:Bus Lock (80486)
486 (20-50MHz) 就支持 dual-socket 了,软件不够,硬件来凑。

自旋锁的缺陷
性能问题 (0)
- 自旋 (共享变量) 会触发处理器间的缓存同步,延迟增加
性能问题 (1)
- 除了进入临界区的线程,其他处理器上的线程都在空转
- 争抢锁的处理器越多,利用率越低
性能问题 (2)
- 获得自旋锁的线程: 可能被操作系统切换出去
- 操作系统不 “感知” 线程在做什么
- (但为什么不能呢?)
- 实现 100% 的资源浪费
看一份自旋锁的代码以验证以上的结论:
头文件:thread-sync.h,还使用了之前的 thread.h
1 |
|
源文件,编译gcc -o sum-scalability sum-scalability.c -O2 -lpthread,运行的时候可以使用:time ./sum-scalability N其中N为线程数,来测试所需要的时间。实际的实验发现,一件事情,开的线程数越多,但时间却耗费得越多。其实就是自旋锁的等待耗费了绝大多数的时间。
1 |
|
使用自旋锁,是一个性能开销较大的方案。
Linux 内核开发中,最常使用的锁是自旋锁。如果线程 A 获得了自旋锁,其他线程再请求锁的时候就无法获得,必须等待线程 A 释放自旋锁。也就是说:一个自旋锁同时只能被一个线程持有,用其保护共享资源就太合适了。
若线程 B 请求一个已经被线程 A 持有的自旋锁,则线程 B 会一直执行类似 while(1); 的自旋动作,直到线程 A 释放自旋锁。能够看出,自旋等待非常耗费处理器,因此任何线程都不应该长时间持有自旋锁。
Linux 内核还有其他类型锁的设计,它会让线程 B 睡眠,直到线程 A 释放自旋锁的时候才重新唤醒线程 B。这样处理器就不必白白把时间花在等待上,而是可以在此期间执行其他代码。那为什么还要设计自旋锁呢?其实,让线程 B 睡眠再唤醒也是有一定的开销的:至少有两次上下文切换。如果这两次上下文切换的开销超出了自旋锁让处理器等待的开销,那明显使用自旋锁更好些。可以看出,自旋锁是一种非常轻量级的设计,在抢占式的 Linux 内核开发中占有非常重要的席位。
自旋锁使用的场景(两个重要的约束)
1、临界区几乎不 “拥堵”
2、持有自旋锁时禁止 执行流切换 (但是实际上,应用程序是做不到的,应用程序能禁止自己被切换出去吗???)
自旋锁真正的使用场景:操作系统内核的并发数据结构 (短临界区) 例如说进程的表啊,或者说我有多少个进程,要被保护起来的数据结构….操作系统可以关闭中断和抢占,保证锁的持有者在很短的时间内可以释放锁(如果是虚拟机呢…😂)。PAUSE 指令会触发 VM Exit。但依旧很难做好。可以看有一篇:《An analysis of Linux scalability to many cores (OSDI’10)》
实现线程 + 长临界区的互斥
作业那么多,与其干等 Online Judge 发布,不如把自己 (CPU) 让给其他作业 (线程) 执行?长临界区肯定不能让处理器去等,而是得干点儿其他的对吧。
等等,上面的 “让” 不是 C 语言代码可以做到的 (C 代码只能计算)
把锁的实现放到操作系统里就好啦!
syscall(SYSCALL_lock, &lk);试图获得 lk,但如果失败,就切换到其他线程syscall(SYSCALL_unlock, &lk);释放 lk,如果有等待锁的线程就唤醒
1 | 换个有趣的视角:操作系统 = 更衣室管理员 |
5-2 互斥锁(Mutex)
互斥锁,POSIX线程库中的互斥锁:pthread_mutex
视线回到5-1中‘自旋锁的缺陷’那一部分的代码,换成互斥锁呢?
1 |
|
编译执行,用time看一看时间,发现时间和自旋锁比起来非常之快,一个线程的时候慢一点点,两个线程发现优势明显,更多的线程,也没有导致摧毁性的后果。我们可以用strace观察系统调用,可以看到非常多次的futex系统调用,那么futex是什么?又如何理解?在绝大部分情况下,都不会出发系统调用,而只有在有争抢的情况下,才会进行系统调用。
5-3 今天的操作系统上的 Futex
自旋锁 (线程直接共享 locked)
更快的 fast path:xchg 成功 → 立即进入临界区,开销很小
更慢的 slow path:xchg 失败 → 浪费 CPU 自旋等待
睡眠锁 (通过系统调用访问 locked)
更快的 slow path:上锁失败线程不再占用 CPU
更慢的 fast path:即便上锁成功也需要进出内核 (syscall)
这俩结合起来:Futex
1 | 在这里插入一个概念:内核态和用户态,这是经常被提及的,对于理解计算机系统来说很重要的概念。 |
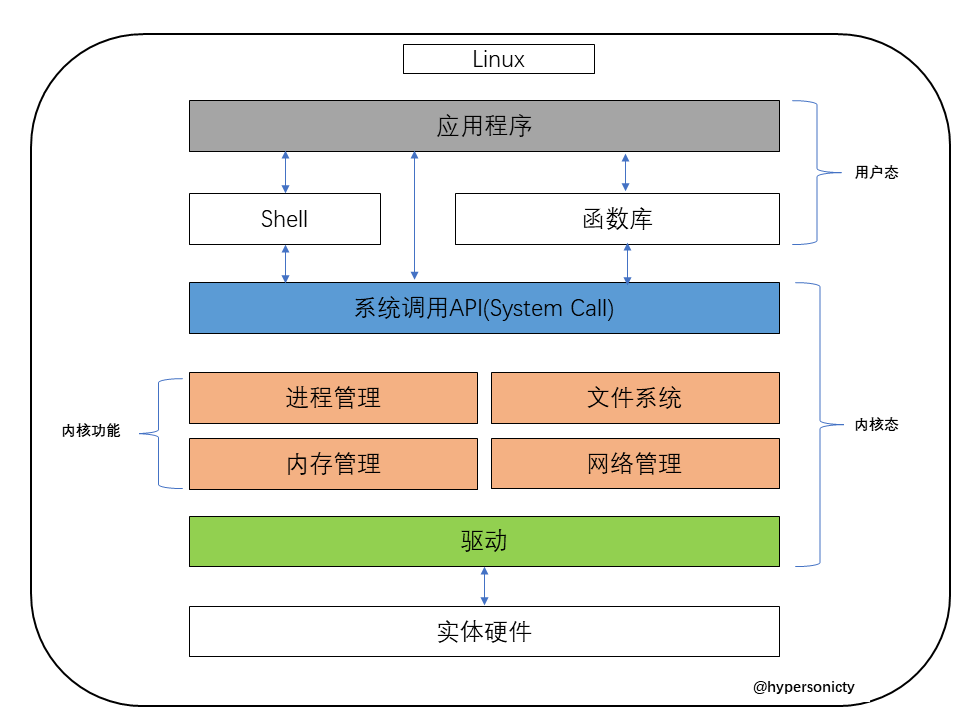

1 | 从上图我们可以看出来通过系统调用将Linux整个体系分为用户态和内核态,为了使应用程序访问到内核的资源,如CPU、内存、I/O,内核必须提供一组通用的访问接口,这些接口就叫系统调用。库函数就是屏蔽这些复杂的底层实现细节,减轻程序员的负担,从而更加关注上层的逻辑实现,它对系统调用进行封装,提供简单的基本接口给程序员。 |
Futex 是Fast Userspace muTexes的缩写,由Hubertus Franke, Matthew Kirkwood, Ingo Molnar and Rusty Russell共同设计完成。几位都是linux领域的专家,其中可能Ingo Molnar大家更熟悉一些,毕竟是O(1)调度器和CFS的实现者。
Futex按英文翻译过来就是快速用户空间互斥体。其设计思想其实不难理解,在传统的Unix系统中,System V IPC(inter process communication),如 semaphores, msgqueues, sockets还有文件锁机制(flock())等进程间同步机制都是对一个内核对象操作来完成的,这个内核对象对要同步的进程都是可见的,其提供了共享的状态信息和原子操作。当进程间要同步的时候必须要通过系统调用(如semop())在内核中完成。可是经研究发现,很多同步是无竞争的,即某个进程进入互斥区,到再从某个互斥区出来这段时间,常常是没有进程也要进这个互斥区或者请求同一同步变量的。但是在这种情况下,这个进程也要陷入内核去看看有没有人和它竞争,退出的时侯还要陷入内核去看看有没有进程等待在同一同步变量上。这些不必要的系统调用(或者说内核陷入)造成了大量的性能开销。为了解决这个问题,Futex就应运而生,Futex是一种用户态和内核态混合的同步机制。首先,同步的进程间通过mmap共享一段内存,futex变量就位于这段共享的内存中且操作是原子的,当进程尝试进入互斥区或者退出互斥区的时候,先去查看共享内存中的futex变量,如果没有竞争发生,则只修改futex,而不 用再执行系统调用了。当通过访问futex变量告诉进程有竞争发生,则还是得执行系统调用去完成相应的处理(wait 或者 wake up)。简单的说,futex就是通过在用户态的检查,(motivation)如果了解到没有竞争就不用陷入内核了,大大提高了low-contention时候的效率。 Linux从2.5.7开始支持Futex。
Futex系统调用 Futex是一种用户态和内核态混合机制,所以需要两个部分合作完成,linux上提供了sys_futex系统调用,对进程竞争情况下的同步处理提供支持。 其原型和系统调用号为
1 |
|
虽然参数有点长,其实常用的就是前面三个,后面的timeout大家都能理解,其他的也常被ignore。uaddr就是用户态下共享内存的地址,里面存放的是一个对齐的整型计数器。
op存放着操作类型。定义的有5中,这里我简单的介绍一下两种,剩下的感兴趣的自己去man futex
FUTEX_WAIT: 原子性的检查uaddr中计数器的值是否为val,如果是则让进程休眠,直到FUTEX_WAKE或者超时(time-out)。也就是把进程挂到uaddr相对应的等待队列上去。 FUTEX_WAKE: 最多唤醒val个等待在uaddr上进程。
可见FUTEX_WAIT和FUTEX_WAKE只是用来挂起或者唤醒进程,当然这部分工作也只能在内核态下完成。有些人尝试着直接使用futex系统调用来实现进程同步,并寄希望获得futex的性能优势,这是有问题的。
应该区分futex同步机制和futex系统调用。futex同步机制还包括用户态下的操作。
Futex同步机制:
1 | 所有的futex同步操作都应该从用户空间开始,首先创建一个futex同步变量,也就是位于共享内存的一个整型计数器。 当进程尝试持有锁或者要进入互斥区的时候,对futex执行"down"操作,即原子性的给futex同步变量减1。如果同步变量变为0,则没有竞争发生, 进程照常执行。如果同步变量是个负数,则意味着有竞争发生,需要调用futex系统调用的futex_wait操作休眠当前进程。 当进程释放锁或者要离开互斥区的时候,对futex进行"up"操作,即原子性的给futex同步变量加1。如果同步变量由0变成1,则没有竞争发生,进程照常执行。如果加之前同步变量是负数,则意味着有竞争发生,需要调用futex系统调用的futex_wake操作唤醒一个或者多个等待进程。 这里的原子性加减通常是用CAS(Compare and Swap)完成的,与平台相关。CAS的基本形式是:CAS(addr,old,new),当addr中存放的值等于old时,用new对其替换。在x86平台上有专门的一条指令来完成它: cmpxchg。 可见: futex是从用户态开始,由用户态和核心态协调完成的。 |
小结:
1. Futex变量的特征
- 1:位于共享的用户空间中
- 2:是一个32位的整型
- 3:对它的操作是原子的
2. Futex在程序low-contention的时候能获得比传统同步机制更好的性能。
3. 不要直接使用Futex系统调用。
4. Futex同步机制可以用于进程间同步,也可以用于线程间同步。
下面给出一份示例代码。
1 | /* |
编译:gcc -o futex futex.cc -lrt
如果看不太懂,可以在第六节之后,再回过头来看这个。
5-4 自旋锁和互斥锁的区别
自旋锁与互斥锁使用层面比较相似,但实现层面上完全不同:当加锁失败时,互斥锁用「线程切换」来应对,自旋锁则用「忙等待」来应对。 它俩是锁的最基本处理方式,更高级的锁都会选择其中一个来实现,比如读写锁既可以选择互斥锁实现,也可以基于自旋锁实现。
本节课回答的问题:
如何在多处理器系统上实现互斥
使用锁。利用一个同步协议,来确保每一次操作都是安全可靠的,不论是读或者写。
6、并发控制:同步
回顾:在第五节中,我们学到了互斥。包括自旋锁、互斥锁、futex。在性能上:拥有锁的人才可以进入临界区,实现了正确的互斥(硬件确保了交换的指令是原子的)如果处理器很多的话,大家都在抢同一把锁,好家伙一人出力其他人围观,更麻烦的是,如果持有锁的这个线程被切换出去了,所有的都在等。那么,把所有锁的代码都移到操作系统内核中去,让系统来管理。
这一节的主题:如何在多处理器上协同多个线程完成任务
是时候开始面对并发编程了?
本次课主要的内容:
- 典型的同步问题:生产者-消费者;哲学家吃饭
- 同步的实现方法:信号量、条件变量
同步的概念
synchronization
两个或者两个以上随时间变化的量在变化过程中保持一定的相对关系。互斥是竞争,同步是协作。互斥是同步的特殊情况。 例如:同步电路,所有的触发器在边沿同时触发。异步就是不同步,例如异步电机,稍微想一想就知道了。
6-1 并发程序中的同步
并发程序的步调很难保证完全一致,这里有个概念:线程同步—在某个时间点共同达到互相已知的状态
再次把线程想象成我们自己

- NPY:等我洗个头就出门/等我打完这局游戏就来
- 舍友:等我修好这个 bug 就吃饭
- 导师:等我出差回来就讨论这个课题
有没有可能编程实现这样的一个协议(状态)?一个线程是自己,一个线程是室友,达成一个“两个人都吃饭”这个函数,一个人完成这个任务,另一个人完成另外一个任务,谁先完成,谁就要等对方,然后一起执行某个事件。
生产者-消费者问题:学会你就赢了
99%的实际并发问题都可以用生产者-消费者模型来解决。还记得之前讲线程的第一节的时候,循环交替打印a和b那个源文件吗?来看下面这段。
1 | void Tproduce() { while (1) printf( "(" ); } |
在 printf 前后增加代码,使得打印的括号序列满足
- 一定是某个合法括号序列的前缀
- 括号嵌套的深度不超过n
- n=3,
((()))合法 - n=3,
(((()))),(()))不合法
- n=3,
- 同步
- 等到有空位再打印左括号
- 等到能配对时再打印右括号
分析:为什么叫 “生产者-消费者” 而不是 “括号问题”?注意,不是 “括号问题”
- 左括号:生产资源 (任务)、放入队列
- 右括号:从队列取出资源 (任务) 执行
能否用互斥锁实现括号问题?
- 左括号:嵌套深度 (队列) 不足 n 时才能打印
- 右括号:嵌套深度 (队列)>1时才能打印
- 当然是等到满足条件时再打印了pc.c
- 用互斥锁保持条件成立
- 压力测试的检查当然不能少:pc-check.py
- Model checker 当然也不能少
- 当然是等到满足条件时再打印了pc.c
注意:队列
1 | /*pc.c:生产者-消费者*/ |
阅读一下这段代码就很清爽知道它在做什么。main开始,n假设为3,开16个线程,count = 0。
- 生产者:初始状态没有上锁,进入函数
Tproduce(),第一步执行上锁的操作,使当前线程进入临界区被保护。n = 3,count = 0,不相等,则if条件不成立,说明:生产者的产出还没有达到边界3。然后执行count++,此时count = 1,然后打印出(当然这个的意是生产了一个左括号在输出缓存区,生产完后解锁释放当前生产者线程。当然,若n = 3,count =3则生产者已经生产了足够的元素,不需要再多(,于是释放资源啊,解锁,等待消费者消费。 - 消费者:初始状态没有上锁,进入函数
Tconsume(),第一步先上锁,保证在消费的时候不受到打扰,如果当前count = 0即代表没有可以消费的产物,于是得解锁释放资源等待,若count!=0,代表有产物可以消费,则将count--,代表当前消费者线程已经消费了一个产物,然后解锁。
for循环创建了8个生产者,8个消费者,一共16个线程,并实现了它们之间的相互协作输出正确的匹配的结果。当然,也可增加消费者或者增加生产者,可以用上面的pc-checker.py来验证它的正确性:./produce_cust x | python3 pc-check.py x,x是正整数随意。这样确保了生产和消费的有序,相当于互相协作,从代码层面上看:条件成立,上锁使用,条件不成立,解锁释放,确保线程的安全且确保互相之间协作的有序性。
6-2 条件变量:万能同步方法
在生产者-消费者的模型中,有没有可能,把这套方法优化一下,在上一段代码中,还是有缺陷,即:不管这个包包(生产者产出的空间)是空的还是满的,每个线程都在尝试把它拿出来“看看”。对吧,这是一个很浪费资源的操作,互斥锁本身就是独占式的,虽然不是自旋锁,但是某种意义上它仍然耗费了很多资源。
同步问题:分析
到底什么时候我们需要同步呢?回到之前的知识,我们看这段代码:
1 | //分两个线程,计算 1+1+1+...+1+1+1+…+1 (共计 2n个 1) |
我们看join()这个函数,其实它就是一个同步,例如说:老师等全班同学都到了才开始上课,有可能学生到了老师没到,或者老师到了学生没到,join()其实就是一个等待,等到某个条件发生之后,它才继续走。
那么:任何同步问题都有先来先等待的条件,这个很重要,理解起来。join()就是等所有线程结束之后再继续执行,看生产者-消费者那段代码:先上一把锁,看看条件成立不成立,不成立就释放掉。实际上retry这个的过程就是一个自旋,检查变量是否符合条件。由此,引出条件变量的知识。
Condition-Variables(条件变量)
把pc.c中的自旋变成睡眠,在完成操作时候唤醒。
条件变量API:
wait(cv, mutex) 💤:调用时必须保证已经获得mutex,释放mutex、进入睡眠状态signal/notify(条件变量)💬:私信:走起。如果有线程正在等待条件变量,则唤醒其中一个线程。broadcast/notifyAll(cv) 📣所有人:走起。唤醒全部正在等待 条件变量 的线程
具体来解释说:以上都是针对条件变量来说的,就好好比一个包包,wait(cv,mutex)就是在我持有互斥锁的时候,把这把锁释放掉,并且让当前持有这个包的线程转过身去睡眠状态。
直到有另外一个线程对同一个条件变量做了一个signal/notify(cv),(前面那个线程是一直沉睡的,因为它不知道什么时候条件才会满足)然后这之后,将会唤醒睡眠的线程,这个线程苏醒后将会重新尝试获得锁。
还有一个broadcast/notifyAll(cv) 📣,就是当前不论有多少个睡眠的,都将会被唤醒,继续执行。
1 |
|
实际上,会出现问题,当有更多的消费者的时候,错误发生了,./produce_cust_cv 2 | head -c 300,观察一下现象,
1 | (())(())(()))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))) |
为啥会这样,原因是:消费者唤醒了消费者线程。
可以简单画张图来看一下。
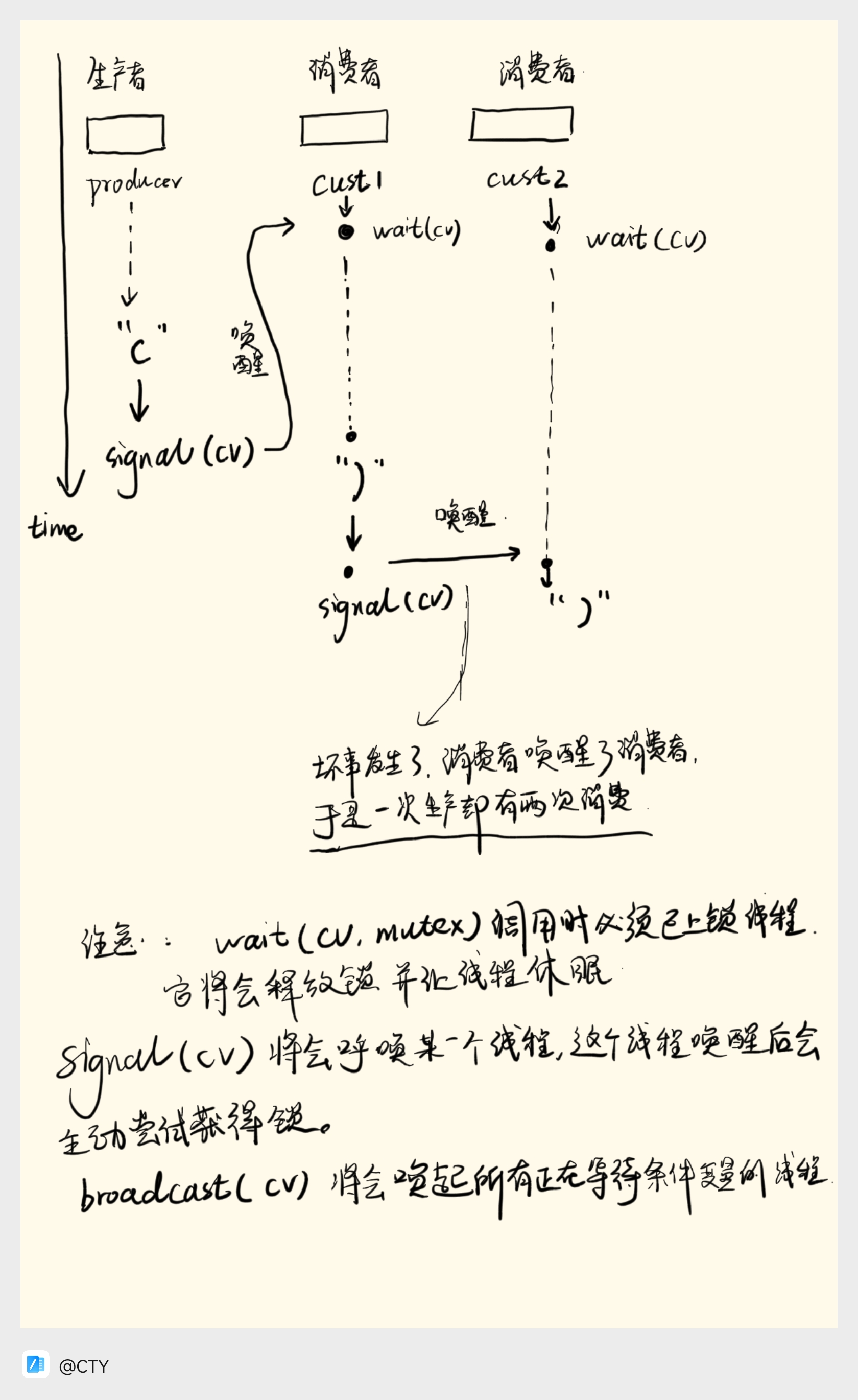

正确的解决方案是需要两个条件变量。
条件变量的正确打开方式:
需要等待条件满足时
1 | mutex_lock(&mutex);//拿住锁,锁阻止了并发 |
其他线程条件可能被满足时
1 | broadcast(&cv);//它将唤醒唤醒全部正在等待 当前条件变量 的线程 |
1 |
|
所以:有了这样一种万能的同步方式,就可以实现并行运算
条件变量:实现并行计算
1 | struct job { |
多个worker来完成一个任务。
6-3 信号量
信号量机制是一种功能较强的机制,用来解决互斥与同步的问题,它只能被两个标准的原语访问:wait和signal,其中wait可以被记为P操作,signal可以被记为V操作。
当然,利用信号量实现同步,是一种经典的做法。
1 | semaphore S = 0; //初始化信号量 |
P2中的语句y需要使用P1中x的运行结果,所以只有当语句x执行完之后语句y才可以继续执行。若P2先执行到P(S),S为0,执行P操作会把进程P2阻塞,并放入阻塞队列;当进程P1中的x执行完之后,执行V(S)操作,把P2从阻塞队列中放回就绪队列,当P2得到处理机时,就可以继续执行。
在之前学到互斥:多个执行链争抢一个共享资源。同步:有多个执行链,等待某种条件,它们之间有序地配合来做一件事情(当然这个定义不太准确),这件事情本身就是共享的。
利用信号量实现:生产者-消费者
1 |
|
它看起来比使用条件变量干净简洁一点,但是会更抽象一些。它在”一单位资源”问题上会更好用些。
代码解读:
1 | 头文件中封了一层SEM_INIT,Linux的sem_init()函数:函数sem_init()用来初始化一个信号量。它的原型为:extern int sem_init __P ((sem_t *__sem, int __pshared, unsigned int __value));sem为指向信号量结构的一个指针;pshared不为0时此信号量在进程间共享,否则只能为当前进程的所有线程共享;value给出了信号量的初始值。这里封的时候默认把第二个参数设置为了0。 |
6-4 哲学家吃饭问题
这个问题是更复杂的并发问题。
6-5 备忘
linux 条件变量和信号量的区别:
- 使用条件变量可以一次唤醒所有等待者,而这个信号量没有的功能,感觉是最大区别。
- 信号量始终有一个值(状态的),而条件变量是没有的,没有地方记录唤醒(发送信号)过多少次,也没有地方记录唤醒线程(wait返回)过多少次。从实现上来说一个信号量可以是用mutex + counter + condition variable实现的。因为信号量有一个状态,如果想精准的同步,那么信号量可能会有特殊的地方。信号量可以解决条件变量中存在的唤醒丢失问题。
- 信号量的意图在于进程间同步,互斥锁和条件变量的意图在于线程间同步,但是信号量也可用于线程间,互斥锁和条件变量也可用于进程间。应当根据实际的情况进行决定。信号量最有用的场景是用以指明可用资源的数量。
经典的一句话:
互斥量是信号量的一种特例,互斥量的本质是一把锁。